

Webscraping tor
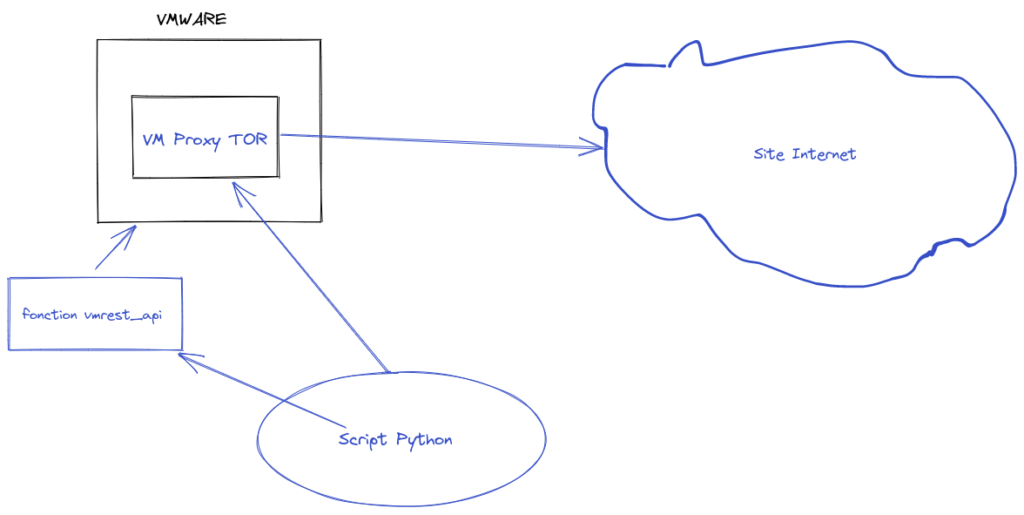
Dans les articles précédents on a vu comment automatiser Vmware et démarrer et arrêter des VM directement dans nos scripts python.
Puis on à vu comment installer un proxy Tor sur une VM.
Justement dans cet article on va voir comment configurer un web scraping proxy tor pour passer inaperçu quand on scrape et éviter les ban IP.
On va aussi voir comment générer un user-agent.

Prérequis – Web scraping proxy Tor
- Vmrest activé
- VM proxy tor configuré
Si ce n’est pas le cas pour vous, vous pouvez suivre les tutos :
On pose les bases
Pour commencer on se place dans notre dossier de travail.
On récupère le projet vmrest_api :
git clone https://gitlab.com/babidi34/vmrest_api.gitRequests avec le proxy tor
On créée notre fichier tor_requests.py puis on import les modules requis
from time import sleep, time
import requests
# for import module vmrest
from vmrest_api import config, vm_fonctions
from stem import Signal
from stem.control import ControllerOn démarre ensuite notre VM tor :
vm_fonctions.power_on(config.id_tor)On initialise notre variable proxies :
proxies = {
'http': 'socks5://172.16.13.50:9050',
'https': 'socks5://172.16.13.50:9050'
}Remplacer « 172.16.13.50 » par l’adresse IP de votre VM tor
Maintenant lançons une requête vers api.ipify pour afficher notre nouvelle IP du réseau TOR :
requete1 = requests.get('https://api.ipify.org', proxies=proxies)
print(requete1.text)Si vous lancez plusieurs fois la requête vous remarquerez que l’adresse IP ne change pas.
Obtenir une iP différente à chaque requête
- Vous devez éditer /etc/tor/torrc sur la VM Tor et ajouter :
ControlPort 9051
ControlPort 172.16.13.50:9051 Remplacer « 172.16.13.50 » par l’adresse IP de votre VM tor
2. Puis on restart le service tor :
systemctl restart tor3. Dans notre script tor_requests.py on ajoute la fonction suivante :
def renew_ip():
with Controller.from_port(address='172.16.13.50',port = 9051) as controller:
controller.authenticate("iopheVoh8soh")
controller.signal(Signal.NEWNYM)
sleep(7)Encore une fois remplacer « 172.16.13.50 » par l’adresse IP de votre VM tor
Dorénavant l’ip de la requête sera renouvelé toute les 5 à 9 secondes dès que vous utiliserez la fonction renew_ip() :
renew_ip()
requete1 = requests.get('https://api.ipify.org', proxies=proxies)
print(requete1.text)On a donc des requêtes qui se lance avec des IP différentes à chaque fois, il ne nous manque plus qu’un user-agent différent à chaque requête.
Random UserAgent
Pour générer un User Agent différent à chaque fois on utilise fake_useragent :
pip install fake_useragentfrom fake_useragent import UserAgentUne fois le module importé, si avant chaque requête on régénère headers :
headers = { 'User-Agent': UserAgent().random }L’user-agent sera différent.
Le code complet de tor_requests.py :
from time import sleep, time
import requests
# for import module vmrest
from vmrest_api import config, vm_fonctions
from fake_useragent import UserAgent
from stem import Signal
from stem.control import Controller
headers = { 'User-Agent': UserAgent().random }
def renew_ip():
with Controller.from_port(address='172.16.13.50',port = 9051) as controller:
controller.authenticate()
controller.signal(Signal.NEWNYM)
sleep(7)
vm_fonctions.power_on(config.id_tor)
renew_ip()
proxies = {
'http': 'socks5://172.16.13.50:9050',
'https': 'socks5://172.16.13.50:9050'
}
requete1 = requests.get('https://api.ipify.org', proxies=proxies,headers=headers)
print(requete1.text)
print(requete1.request.headers)
renew_ip()
headers = { 'User-Agent': UserAgent().random }
requete2 = requests.get('https://api.ipify.org', proxies=proxies,headers=headers)
print(requete2.text)
print(requete2.request.headers)J’ai lancé intentionnellement 2 requêtes pour afficher les différences d’IP et d’user agent.
Selenium firefox avec le proxy tor
script tor_selenium.py
Les modules à importer :
from time import sleep, time
# for import module vmrest
from vmrest_api import config, vm_fonctions
from stem import Signal
from stem.control import Controller
from selenium import webdriverLa différence avec requests et que l’on va devoir créer une fonction profil_proxy qui sera utilisé dans notre requête selenium :
def profil_proxy():
ip_tor = "172.16.13.50"
port_tor = 9050
profile = webdriver.FirefoxProfile()
profile.set_preference("network.proxy.type", 1)
profile.set_preference("network.proxy.socks", ip_tor)
profile.set_preference("network.proxy.socks_port", port_tor)
profile.set_preference("network.proxy.socks_version", 5)
profile.update_preferences()
return profile
url = "https://api.ipify.org"
profile = profil_proxy()
driver = webdriver.Firefox(firefox_profile=profile)
driver.get(url)Selenium utilisera alors votre navigateur Firefox configuré sur le proxy de votre VM Tor.
Code complet du script tor_selenium.py :
from time import sleep, time
# for import module vmrest
from vmrest_api import config, vm_fonctions
from stem import Signal
from stem.control import Controller
from selenium import webdriver
def renew_ip():
with Controller.from_port(address='172.16.13.50',port = 9051) as controller:
controller.authenticate("iopheVoh8soh")
controller.signal(Signal.NEWNYM)
def profil_proxy():
ip_tor = "172.16.13.50"
port_tor = 9050
profile = webdriver.FirefoxProfile()
profile.set_preference("network.proxy.type", 1)
profile.set_preference("network.proxy.socks", ip_tor)
profile.set_preference("network.proxy.socks_port", port_tor)
profile.set_preference("network.proxy.socks_version", 5)
profile.update_preferences()
return profile
vm_fonctions.power_on(config.id_tor)
url = "https://api.ipify.org"
profile = profil_proxy()
driver = webdriver.Firefox(firefox_profile=profile)
driver.get(url)
sleep(3)
driver.close()
renew_ip()
driver = webdriver.Firefox(firefox_profile=profile)
driver.get(url)
sleep(3)
driver.close()Comme pour le script précédent, ce script démarre la VM tor, set les requêtes sur le proxy tor et renouvelle l’adresse IP avant chaque requête.
Aller plus loin
Maintenant que vous savez faire des requêtes en utilisant le réseau tor et en utilisant un faux user-agent, vous êtes en mesure de scraper le web de manière anonyme.
Si vous souhaitez en savoir plus sur les manière de scraper le web, vous pouvez suivre ce tuto : WEBSCRAPING