
terrain note
Vector database self hosted : guide pour une base vectorielle privée
Guide pratique pour choisir, tester et sécuriser une vector database self hosted dans un contexte IA/RAG B2B.
Linux · DevOps · Cloud · FinOps
J’aide les équipes tech à sécuriser leur production, fiabiliser leurs déploiements et reprendre le contrôle de leurs coûts cloud, avec un accompagnement pragmatique et actionnable.
Premier échange sans engagement : on clarifie votre contexte, vos risques et les prochaines actions possibles. Pas d’effet tunnel, pas de jargon inutile.
Ils m’ont fait confiance
Linux-Man intervient quand l’infrastructure fonctionne encore, mais que les risques deviennent visibles : dérive cloud, dépendance humaine, sauvegardes incertaines ou delivery fragile.
Le but n’est pas de tout refaire. Le but est de savoir ce qui menace la production, ce qui coûte trop cher, et quelles actions donnent le meilleur ratio impact / effort.
Analyser mon contexte →Chaque recommandation est reliée à un risque, un impact ou un gain opérationnel. Vous savez ce qui est fait, pourquoi c’est fait, ce qui reste à décider et ce qui peut attendre.
Les problèmes ne sont pas seulement listés : ils sont expliqués avec leur cause probable, leur impact et leur priorité.
Vous obtenez une trajectoire claire : quick wins, corrections prioritaires, chantiers de fond et points à surveiller.
Les décisions importantes sont tracées. Vous gardez la visibilité sur l’avancement, les compromis et les risques restants.
L’objectif est une infrastructure plus fiable, mais aussi plus compréhensible pour les personnes qui l’exploitent.
terraform plan
On lit l’existant, on détecte les dérives et on transforme les constats en plan d’action priorisé.
terraform apply
On stabilise l’existant, on documente les décisions et on accompagne l’équipe dans la durée.
Contexte, contraintes, accès, urgence, objectifs métier et périmètre réel.
Sécurité, exploitation, sauvegardes, observabilité, delivery et coûts cloud.
Risques critiques, quick wins, arbitrages et trajectoire 30/60/90 jours.
Actions concrètes, documentation, décisions tracées et amélioration continue.
Un accompagnement Linux-Man doit produire des éléments utiles après la mission : de quoi décider, agir, documenter et transmettre.
Constats, risques, contexte et recommandations compréhensibles.
Impact, effort, urgence, dépendances et quick wins.
Commandes, playbooks ou procédures quand c’est pertinent.
Explications claires pour profils techniques et non techniques.
Une trajectoire réaliste pour réduire les risques durablement.
Linux-Man intervient là où l’infrastructure touche directement la disponibilité, la sécurité, la capacité à livrer et les coûts. L’objectif n’est pas de tout refaire, mais de rendre les priorités visibles et exécutables.
Réserver un échange de cadrageL’expertise Linux-Man se vérifie dans les sujets concrets du quotidien : exploitation, sécurité, automatisation, coûts cloud, supervision et transmission aux équipes.
Debian, Ubuntu, accès SSH, durcissement, patching, sauvegardes, restauration et exploitation courante.
Playbooks Ansible, scripts contrôlés, standards reproductibles et réduction des opérations manuelles fragiles.
Ressources oubliées, surdimensionnement, alertes budget, arbitrages hébergement et trajectoire de réduction des coûts.
CI/CD, GitLab, procédures de release, rollback, environnements et réduction des dépendances humaines.
Supervision, alertes actionnables, signaux faibles, réduction du bruit et meilleure lecture des incidents.
Runbooks, schémas, décisions, limites connues et explications pour rendre l’équipe autonome.
principe de collaboration
La confiance vient aussi de limites explicites. Mon rôle est de rendre votre infrastructure plus fiable et plus lisible, pas de créer une dépendance ou d’ajouter de la complexité inutile.
« Karim a travaillé avec nous sur plusieurs missions… infrastructure parfaitement sécurisée et fonctionnelle, maintenant utilisée en production… support précieux lors des appels techniques avec des prestataires externes. »
Tony Caron, CTO (Heyteam)« Karim est un professionnel très qualifié, force de proposition, et il sait s’adapter au contexte. Un prestataire de son niveau est un atout précieux pour notre entreprise. »
Steve Bercy, CEO (Airzoon)« Merci Karim pour votre travail rigoureux et rapide. Je recommande ! Karim a su répondre exactement à notre problématique, avec sérieux, efficacité et professionnalisme dans le respect de nos contraintes budgétaires. »
François, Zero SixLes derniers articles servent de preuve d’expertise continue : sécurité, exploitation Linux, automatisation et méthodes terrain.

Guide pratique pour choisir, tester et sécuriser une vector database self hosted dans un contexte IA/RAG B2B.

AI DevOps : cas d’usage, risques, architecture et mini-lab pour intégrer l’IA dans l’exploitation sans perdre le contrôle.
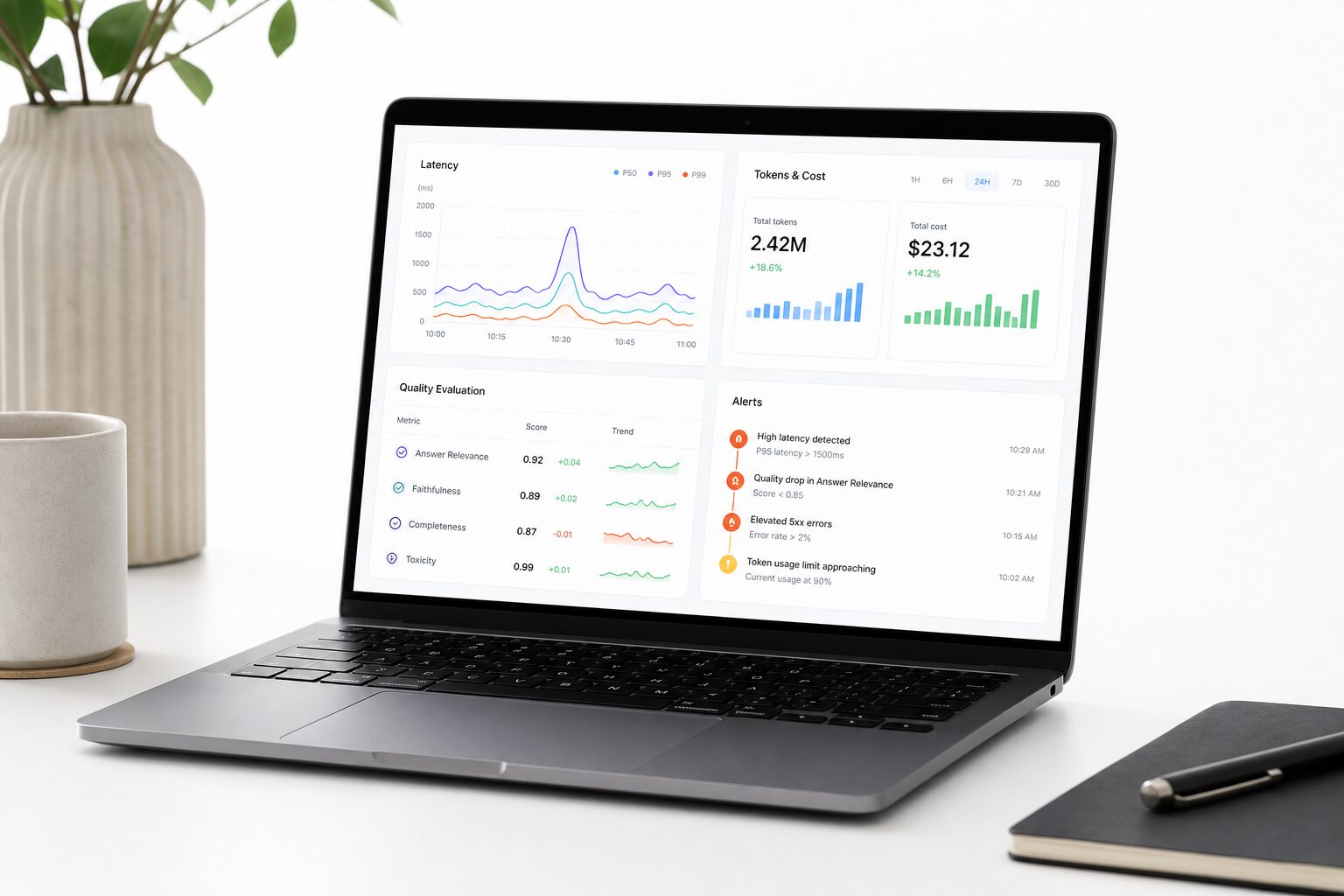
AI observability : guide concret pour définir signaux, SLI, SLO, coûts et garde-fous d’un service IA en production.
On fait un échange court pour identifier vos priorités : risques, supervision, backups, coûts cloud ou delivery.
Premier échange sans engagement : vous repartez avec une première lecture des risques, des priorités et des options possibles.