

BITBUCKET · ANSIBLE · CI/CD
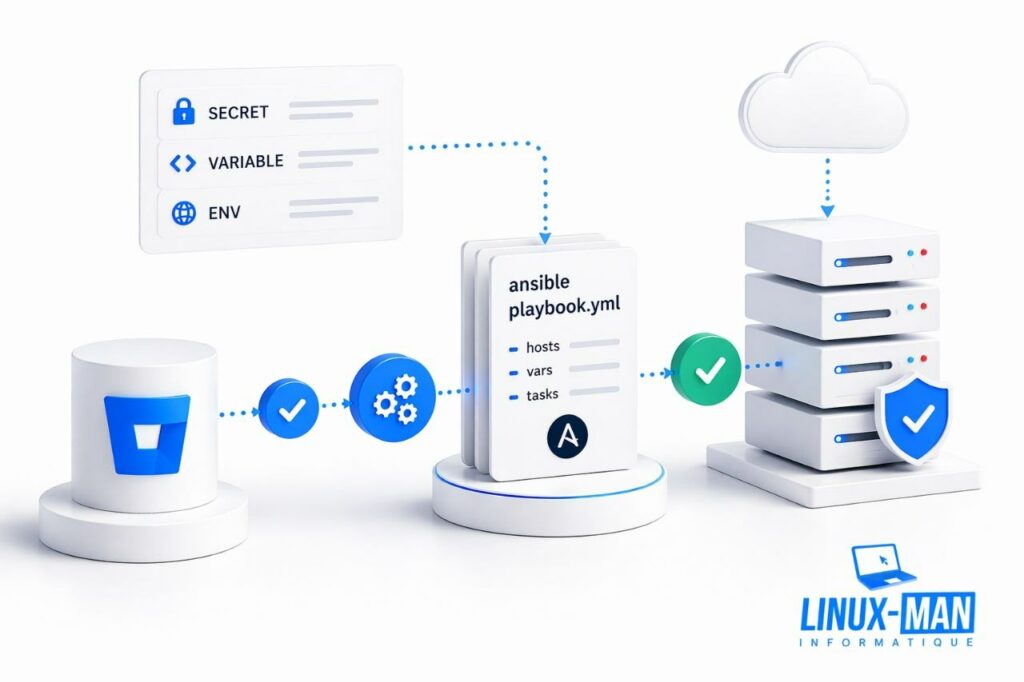
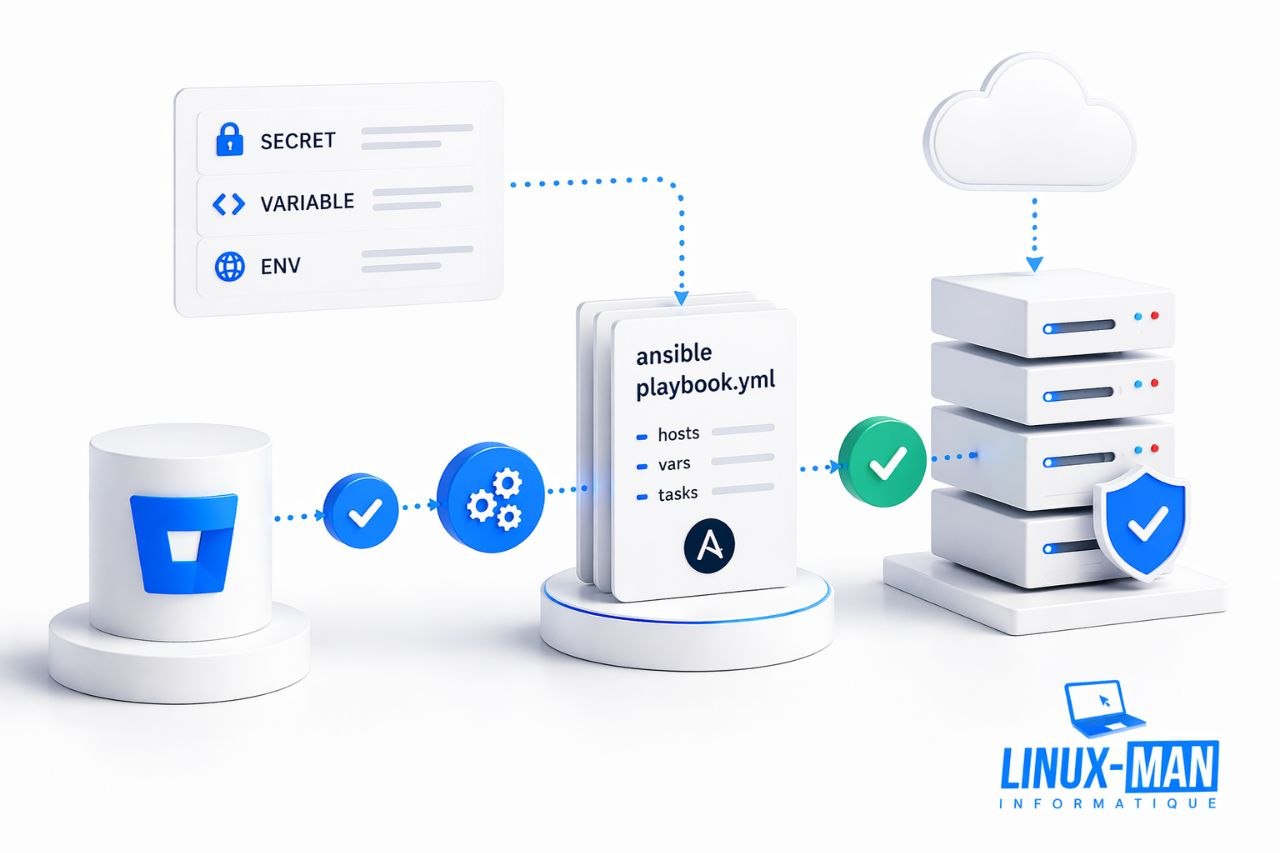
Si tu gères plusieurs environnements dans Bitbucket, les variables de déploiement Bitbucket deviennent vite pénibles à maintenir à la main. J’ai créé un rôle Ansible pour reprendre ça proprement : supprimer les anciennes valeurs si besoin, puis recréer un état cohérent sans passer mon temps dans l’interface web. Les UUID d’environnements sont détectés automatiquement à partir du nom..

📋 Au programme
Les bitbucket deployment variables servent à isoler tes valeurs selon l’environnement ciblé, mais dès que tu multiplies les clés, les révisions manuelles deviennent fragiles. Le plus simple est de déclarer l’état attendu dans Ansible puis de laisser l’automatisation remettre Bitbucket d’équerre. Si tu veux fiabiliser plus largement tes serveurs et tes déploiements, tu peux aussi jeter un œil à mon offre d’infogérance de serveurs Linux en entreprise.
Réponse rapide
Pour gérer proprement les variables Bitbucket, je décris mes valeurs dépôt et environnement dans Ansible, le rôle détecte automatiquement les UUID d’environnements à partir de leur nom, je remplace l’existant si nécessaire et je rejoue la même configuration sans dérive. Résultat : moins de clics, moins d’oublis et une base plus simple à reprendre.
Pourquoi les variables Bitbucket deviennent vite ingérables
Sur le papier, modifier quelques variables dans Bitbucket n’a rien de compliqué. En pratique, ça se dégrade très vite dès que tu dois gérer plusieurs environnements, plusieurs clés sensibles et plusieurs personnes qui interviennent sur le même dépôt. Une valeur change, une clé est renommée, un environnement de préproduction est ajouté, et tu te retrouves avec une configuration qui n’existe nulle part ailleurs que dans l’interface.
Le vrai problème n’est pas Bitbucket lui-même. Le vrai problème, c’est l’absence d’état déclaré. Si tout repose sur des manipulations manuelles, tu perds la traçabilité, tu augmentes le risque d’écart entre dev, préprod et production, et tu rends chaque évolution plus stressante qu’elle ne devrait l’être.
J’ai monté ce rôle précisément pour éviter ça. Mon objectif n’était pas de faire un gadget, mais d’avoir un moyen simple de gérer les variables dépôt et les variables liées aux environnements avec la même logique que le reste de mon infra : description claire, exécution rejouable et résultat prévisible.
Le bénéfice concret
Quand les variables sont décrites dans Ansible, tu peux relire l’état attendu, le versionner, le réviser et le rejouer. Tu ne dépends plus d’une mémoire approximative ou d’une capture d’écran prise un soir en urgence.
Ce que fait concrètement mon rôle Ansible
Le rôle Ansible que j’ai conçu à l’origine pour gérer les configurations Bitbucket de mes clients. Il repose sur une logique volontairement simple. Le fichier tasks/main.yml orchestre deux étapes : gérer les variables du dépôt, puis gérer les variables propres à chaque environnement. La détection des UUID d’environnements est automatique à partir du nom.
- name: Set repository variables
include_tasks: repo_vars.yml
- name: Set deploy variables
include_tasks: deploy_vars.ymlLe rôle détecte automatiquement les UUID d’environnements à partir de leur nom — pas besoin de les déclarer dans les variables du playbook. Il interroge l’API Bitbucket en interne et construit la correspondance tout seul.
Ensuite, pour les variables dépôt comme pour les variables d’environnement, le rôle suit la même stratégie : lire l’existant, repérer les clés déjà présentes, supprimer les anciennes entrées si nécessaire, puis recréer l’état cible. Dit autrement : je ne rajoute pas des couches à l’aveugle, je remets un état cohérent.
Si tu veux un cadre plus large autour des changements serveur, de la reprise d’existant ou de l’automatisation quotidienne, ma page maintenance de serveurs Linux donne le contexte de ce que je mets en place autour de ce genre d’outillage.
Comment structurer dépôt, environnements et variables
Pour que cette méthode reste lisible, je sépare toujours deux niveaux :
🧱
Variables dépôt
Elles valent pour tout le dépôt : identifiants communs, endpoints partagés, options globales.
🌍
Variables environnement
Elles changent selon dev, préprod ou production : hôte SSH, port, répertoire cible, options spécifiques.
🔒
Valeurs sécurisées
Le rôle sait envoyer le drapeau secured pour éviter d’exposer inutilement une valeur sensible.
♻️
État rejouable
Tu peux relancer la même description après un changement, une reprise ou un audit.
Dans le README, la structure attendue reste très claire : un workspace, un dépôt, un header d’authentification, puis une liste d’environnements avec leurs variables. C’est ce que j’aime dans ce genre de dépôt : tu comprends vite où agir sans avoir besoin d’un mode d’emploi de 20 pages.
environment_variables:
- environment: "dev"
variables:
- key: "SSH_HOST"
value: "dev.server.com"
secured: false
- key: "SSH_PORT"
value: "22"Cette séparation est aussi plus simple à auditer. Quand un incident arrive, tu peux revoir l’état visé, vérifier la valeur d’une clé pour un environnement précis et corriger sans replonger dans l’interface.
Mise en place pas à pas
La mise en œuvre peut rester très sobre. L’idée n’est pas d’empiler des abstractions, mais de poser une base stable.
✅ Checklist de départ
workspace et le dépôt viséssecured: true pour les valeurs qui ne doivent pas être visiblesVoici une base de playbook très simple pour appeler le rôle :
---
- hosts: localhost
gather_facts: false
roles:
- role: bitbucket_env_vars
vars:
bitbucket_workspace: "<WORKSPACE>"
bitbucket_repo: "<REPOSITORY>"
bitbucket_auth: "Basic <BASE64_USER_APP_PASSWORD>"
repository_variables:
- key: "APP_ENV"
value: "production"
secured: false
environment_variables:
- environment: "production"
variables:
- key: "SSH_HOST"
value: "prod.example.net"
secured: false
- key: "SSH_USER"
value: "deploy"
secured: falseCe que j’aime dans cette approche, c’est qu’elle reste lisible même plusieurs mois plus tard. Tu n’as pas à te demander quelle clé a été créée à la main ni sur quel environnement la dernière modification a été faite.
Et si tu dois remettre à plat plus largement les configurations applicatives ou système autour de tes déploiements, ma page services de configuration serveurs résume bien le type d’accompagnement que je fais autour de ces sujets.
Les points de sécurité à garder en tête
Automatiser la gestion des variables ne veut pas dire relâcher la sécurité. Au contraire. Dès que tu centralises ce type d’information, tu dois être encore plus rigoureux sur le contenu réellement stocké et sur les accès qui peuvent le modifier.
Erreur classique
Beaucoup d’équipes gardent des anciennes clés sensibles qui ne servent plus, simplement parce que personne n’ose nettoyer. Le rôle Ansible aide justement à repartir d’un état propre au lieu d’empiler les restes.
Mes garde-fous habituels :
- limiter les droits de l'accès API Bitbucket
- marquer comme sécurisées les valeurs sensibles
- éviter les noms de variables ambigus
- nettoyer les anciennes clés devenues inutiles
- versionner la description de l’état attendu
- relire régulièrement l’écart entre besoin réel et valeurs présentesÀ éviter absolument
Ne colle pas des secrets réels dans un exemple de documentation, ne recycle pas un accès trop large pour gagner 5 minutes, et n’utilise pas l’interface comme source de vérité unique. Tu gagnes peut-être du temps sur le moment, mais tu compliques tout le reste.
Erreurs fréquentes quand on automatise les variables Bitbucket
🧩 Mélanger variables globales et variables d’environnement
Quand tout est au même niveau, tu ne sais plus ce qui doit rester commun et ce qui doit diverger entre dev, préprod et production.
🕵️ Oublier le nettoyage des anciennes clés
Une clé obsolète peut continuer à semer le doute longtemps après la fin de son usage réel.
📄 Ne pas documenter les environnements
Si personne ne sait à quoi correspondent les valeurs déclarées, l’automatisation reste technique mais pas vraiment exploitable.
🔁 Corriger à la main après coup
Si tu modifies ensuite les mêmes valeurs dans l’interface sans remettre Ansible à jour, tu recrées l’écart que tu cherchais justement à supprimer.
FAQ
▶ Pourquoi utiliser Ansible pour des variables Bitbucket ?
▶ Le rôle sait-il gérer les UUID d’environnements automatiquement ?
▶ Peut-on séparer variables dépôt et variables environnement ?
▶ Faut-il supprimer l’existant avant de recréer les variables ?
▶ Cette méthode remplace-t-elle une revue de sécurité ?
Autre avantage souvent sous-estimé : quand la description de tes variables vit dans le même dépôt que le reste de ton automatisation, tu facilites aussi la revue technique. Une personne extérieure peut comprendre ce qui change, valider la logique d’environnement et détecter plus vite une incohérence entre la cible voulue et la valeur réellement appliquée. Pour une équipe qui veut réduire les surprises en mise en service, ce simple point change beaucoup de choses.
Conclusion
Gérer les variables Bitbucket à la main peut tenir un temps. Mais dès que ton dépôt bouge, que les environnements se multiplient ou que plusieurs personnes interviennent, cette méthode montre vite ses limites. C’est pour ça que j’ai préféré écrire un rôle Ansible simple, relisible et rejouable.
Si tu veux remettre au propre ta gestion des variables, fiabiliser tes déploiements ou cadrer plus largement ton automatisation, contacte-moi via cette page de contact.
Tu veux reprendre proprement tes variables et tes déploiements ?
Je peux t’aider à remettre à plat la gestion des variables, la logique d’environnement et l’automatisation autour de Bitbucket et de tes serveurs Linux.