Elastic Stack · Logs · Observabilité
Logstash est le moteur de transformation de la stack ELK. Il sert à ingérer, parser, enrichir et router des logs avant leur envoi vers Elasticsearch, puis leur exploitation dans Kibana. Dans ce guide, je montre l’installation de Logstash, les bases de configuration input/filter/output et un pipeline ELK complet pour centraliser des logs Linux proprement.

📋 En bref
- But : installer et configurer Logstash pour construire un pipeline ELK propre
- Cas d’usage : parser, enrichir et router des logs Linux ou applicatifs
- Stack : Logstash, Filebeat, Elasticsearch, Kibana
- Dans ce guide : installation, configuration input/filter/output, pipeline et debug
Ici nous utiliserons des inputs de type logs et container pour l’exemple mais il faut savoir qu’en plus des logs classiques, cet outil prend en charge une multitude de données :
- Azure event hub
- TCP
- UDP
- Syslog
- http
- Kafka
- sqlite
- S3
et bien d’autres, vous avez la liste ici.
Pré-requis pour suivre ce tuto
- Avoir un serveur Elasticsearch et Kibana d’installé et configuré, si ce n’est pas le cas, tu peux voir ces tutos :
2. Avoir une seconde VM linux avec Apache ou Nginx d’installé
Installation de Logstash
Installation avec docker
docker pull docker.elastic.co/logstash/logstash:7.10.2docker run -d --name logstash --link elasticsearch:elasticsearch -p 5044:5044 -p 5045:5045 --volume $PWD:/etc/logstash docker.elastic.co/logstash/logstash:7.10.2 Avantages d’utiliser Logstash avec docker :
- Isolation : Tu peux aussi avoir plusieurs instances de Logstash, chacune avec sa propre configuration, sans avoir à créer de machines virtuelles ou à gérer plusieurs installations de Logstash sur le même serveur.
- Portabilité : en mettant Logstash dans un conteneur, tu peux facilement déplacer ton installation sur un autre serveur ou dans le cloud. Il suffit de récupérer le conteneur et de le démarrer sur la nouvelle machine.
- Mise à jour facile : il est facile de mettre à jour Logstash en utilisant la dernière version disponible grâce aux images Docker. Il suffit de télécharger l’image mise à jour et de la démarrer pour remplacer l’ancienne instance de Logstash.
- Gestion simplifiée : avec un Docker Compose pour définir toutes les dépendances de Logstash (par exemple, Elasticsearch et Kibana) dans un fichier de configuration unique, ce qui simplifie la gestion de votre stack ELK.
Installation sur Debian/Ubuntu
- On télécharge et installe la clé publique :
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -2. On installe le paquet suivant :
sudo apt-get install apt-transport-https3. On ajoute le dépôt distant dans nos sources :
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list4. On télécharge et installe notre ami :
sudo apt-get update && sudo apt-get install logstash5. On le démarre et l’active par défaut au démarrage :
service logstash start
systemctl enable logstashInstallation sous Centos
- On télécharge et installe la clé publique :
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch2. On crée un fichier logstash.repo dans /etc/yum.repos.d/ qui contiendra :
[logstash-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md3. On l’installe :
sudo yum install logstash4. On le démarre et l’active par défaut au démarrage :
service logstash start
systemctl enable logstashInput et Output simple
Pour cet exemple, j’utilise un serveur Centos 8 avec Apache, sur ce serveur on installera le module Filebeat et nous le configurerons pour qu’il envoie les logs access de notre apache vers notre serveur L.
Le serveur L réceptionnera les logs, les structurera via un grok puis les enverra vers notre serveur Elasticsearch.
- On installe filbeat sur notre Centos Apache :
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.10.1-x86_64.rpm
sudo rpm -vi filebeat-7.10.1-x86_64.rpm2. Puis on lance le service :
sudo filebeat setup
sudo service filebeat start
systemctl enable filebeat # si on souhaite activer filebeat par défaut au démarrage3. De base filebeat est fait pour renvoyer nos logs vers Elasticsearch, on va donc éditer /etc/filebeat/filebeat.yml pour faire en sorte que Filebeat renvoie nos logs vers notre serveur L, dans un premier temps on commente la partie output Elasticsearch :
#output.elasticsearch:
# hosts: ["<es_url>"]
# username: "elastic"
# password: "<password>"4. Ensuite, on décommente la partie output.logstash et on ajoute l’url de notre serveur L :
output.logstash:
# The Logstash hosts
hosts: ["172.16.13.1:5044"]
5. Toujours dans /etc/filebeat/filebeat.yml, on se rend à la partie filebeat.inputs et on ajoute ce bout de code :
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/*/access_logQui permet d’activer les inputs de type log et de lui donner le chemin vers nos logs.
J’ai fait au plus simple mais j’aurais aussi pu lui donner accès à plusieurs logs avec :
- /var/log/{httpd,nginx}/*Et on pourrais également affiner notre extraction de logs avec les lignes :
- exclude_lines: qui permet d’indiquer les lignes à ne pas prendre en compte
- exclude_files: les fichiers à exclure
- ignore_older: pour ignorer les fichiers vieux de X jours/heures/minutes
On peut aussi ajouter des champs avec fields, exemple :
fields:
service: Apache
site: e-commerceToutes les informations sur filebeat.inputs se trouve sur la documentation officielle.
6. On retourne sur notre serveur L, on crée un dossier pattern dans /etc/logstash :
mkdir /etc/logstash/pattern7. Ce dossier contiendra les pattern à utiliser pour traiter nos logs inputs, on crée donc un fichier nginx-apache dans /etc/logstash/pattern qui contient :
NGUSERNAME [a-zA-Z\.\@\-\+_%]+
NGUSER %{NGUSERNAME}8. Enfin on crée un fichier de conf nommé nginx-apache.conf dans /etc/logstash/conf.d. Ce fichier indique à notre serveur L, comment transformer nos logs inputs avec un grok et vers où il doit envoyer ces logs.
/etc/logstash/conf.d/nginx-apache.conf :
input {
beats {
port => 5044
}
}
filter {
grok {
patterns_dir => "/etc/logstash/pattern"
match => { "message" => "%{IPORHOST:clientip} %{NGUSER:ident} %{NGUSER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response}" }
}
}
output {
elasticsearch {
hosts => ["172.16.13.1:9200"]
index => "nginx-apache%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}la partie « grok » indique où trouver les pattern et elle indique à quoi correspond chaque partie d’une ligne de code, ce qui permettra d’avoir des logs structuré dans notre Elasticsearch.
Des sites nous offrent les patterns et grok déjà fait :
- https://grokdebug.herokuapp.com/
- https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns
Dans la partie Output, on entre en hosts l’url de notre ES puis la ligne index nous permet d’entrer un nom d’index pour nos logs envoyé. « nginx-apache%{+YYYY.MM.dd} » permettra d’avoir un index différent nginx-apache chaque jour.
9. Maintenant que tout est configuré on restart notre serveur L et notre filebeat :
# sur le serveur L
service restart logstash# sur le serveur Apache
service restart filebeatNos logs sont maintenant traité et envoyé vers notre serveur Elasticsearch, on peut alors les exploiter avec notre serveur Kibana.
En allant dans Index Management sur notre kibana, on peut voir nos logs :
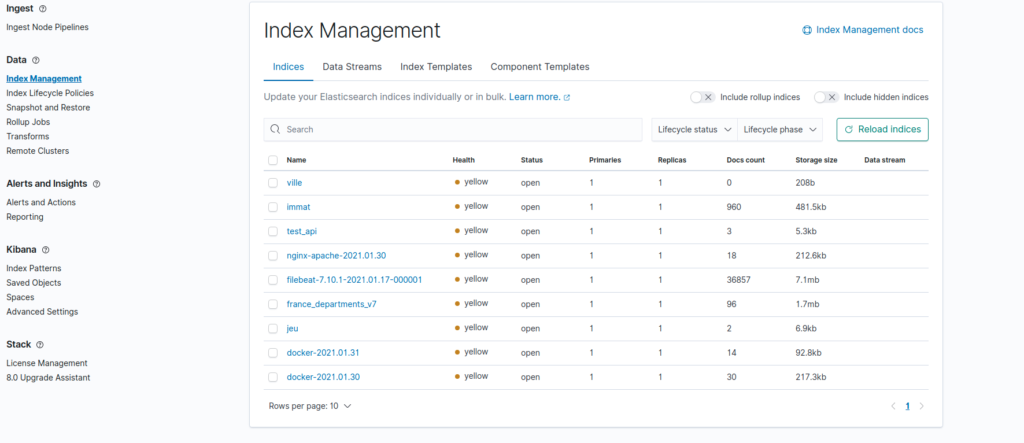

Pour les exploiter nous devons créer un index pattern dans kibana, on clique alors sur Index Patterns dans la partie Kibana, on clique sur create Patterns et on lui donne le nom des logs à utiliser ici nginx-apache :
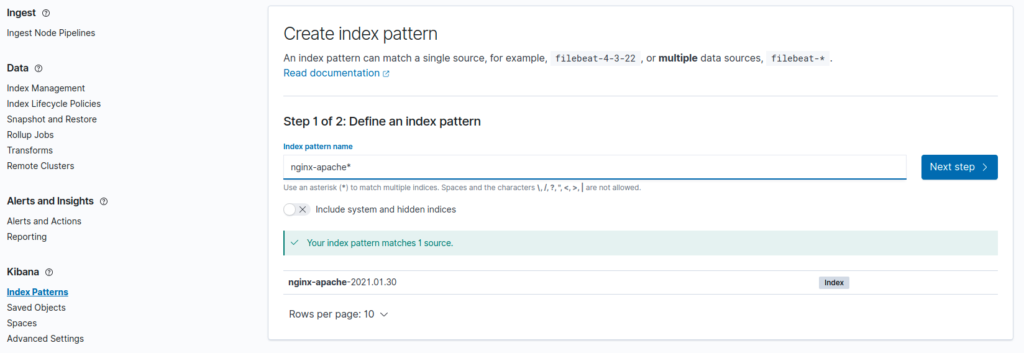
Puis on lui indique qu’il faut utiliser le @timestamp comme field time (@timestamp est fourni par défaut par notre filebeat) :
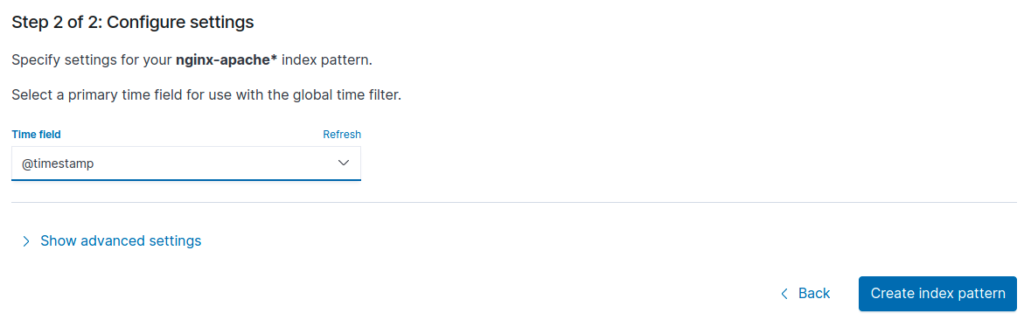
On peut alors visualiser nos logs dans Discover de la même manière qu’expliqué dans le tuto sur l’exploitation des logs avec Kibana.
Multi input et Output
On a vu comment créer un input, un filter et un output, maintenant on va voir comment faire si notre serveur L reçoit plusieurs Input et en faire plusieurs Output, pour faire en sorte d’avoir un index pour chaque input sur notre serveur ES.
On va utiliser la même infrastructure que précédemment mais cette fois on va rajouter un container sur notre serveur Apache. J’utilise un conteneur PostgreSQL pour l’exemple.
- Sur notre serveur Apache, on télécharge l’image docker et on lance le conteneur postgresql :
docker pull postgres:alpine
docker run --name postgres -e POSTGRES_PASSWORD=1234 -p 5432:5432 -d postgres:alpine 2. On retourne éditer le fichier /etc/filebeat/filebeat.yml, dans la partie filebeat.inputs on rajoute :
- type: container
enabled: true
paths:
- '/var/lib/docker/containers/*/*.log'On indique qu’on utilise des données container cette fois et on lui donne le chemin vers les logs de notre container.
Les logs des conteneurs docker se trouve dans /var/lib/docker/containers/nom_du_container/fichier.log
3. Puis on retourne sur notre serveur L et on modifie le fichier de conf de cette manière :
# fichier /etc/logstash/conf.d/nginx-apache.conf
input {
beats {
port => 5044
}
}
filter {
if [input][type] == "log" {
grok {
patterns_dir => "/etc/logstash/pattern"
match => { "message" => "%{IPORHOST:clientip} %{NGUSER:ident} %{NGUSER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response}" }
}
mutate {
add_tag => ["log apache"]
}
}
if [input][type] == "container" {
grok {
patterns_dir => "/etc/logstash/pattern"
match => { "message" => "%{DATESTAMP:timestamp} %{TZ} %{DATA:user_id} %{GREEDYDATA:connection_id} %{POSINT:pid}" }
}
mutate {
add_tag => ["docker"]
}
}
}
output {
if "log apache" in [tags] {
elasticsearch {
hosts => ["172.16.13.1:9200"]
index => "nginx-apache-%{+YYYY.MM.dd}"
}
}
if "docker" in [tags] {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "docker-%{+YYYY.MM.dd}"
}
}
stdout { codec => rubydebug }
}
Ce fichier de configuration permet de gèrer les multi input et faire des outputs individuellement.
Dans un premier temps, si l’input est de type « log » on utilise le grok pour nginx/apache et on lui attribue le tag « log apache » :
mutate {
add_tag => ["log apache"]
}Mais si l’input est de type « container » on utilise le grok pour postgres ( car on utilise un conteneur postgres) et on lui attribue le tag « docker ».
filter {
if [input][type] == "log" {
grok {
patterns_dir => "/etc/logstash/pattern"
match => { "message" => "%{IPORHOST:clientip} %{NGUSER:ident} %{NGUSER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response}" }
}
mutate {
add_tag => ["log apache"]
}
}
if [input][type] == "container" {
grok {
patterns_dir => "/etc/logstash/pattern"
match => { "message" => "%{DATESTAMP:timestamp} %{TZ} %{DATA:user_id} %{GREEDYDATA:connection_id} %{POSINT:pid}" }
}
mutate {
add_tag => ["docker"]
}
}
}A ce niveau on a nos 2 inputs traiter, maintenant pour gérer les outputs notre fichier de conf va utiliser les tags que l’on vient d’attribuer.
Si le tag est « log apache » les logs sont envoyé sur l’index nginx-apache* tandis que si le tag est « docker » l’index sera docker-*
output {
if "log apache" in [tags] {
elasticsearch {
hosts => ["172.16.13.1:9200"]
index => "nginx-apache-%{+YYYY.MM.dd}"
}
}
if "docker" in [tags] {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "docker-%{+YYYY.MM.dd}"
}
}
stdout { codec => rubydebug }
}4. Enfin on restart notre L et notre filebeat :
# sur le serveur L
service restart logstash# sur le serveur Apache
service restart filebeatOn peut maintenant visualiser nos data sur Kibana dans Index Management, crée des patterns avec et exploiter nos index dans Discover.
Aller plus loin avec Logstash
- Tu peux utiliser logstash pour réceptionner différentes sources de logs, comme rsyslog ou http, kafka et autres.
- Ajouter des fonctionnalités supplémentaires à Logstash (par exemple, pour envoyer des notifications par e-mail en cas d’erreur, ou pour traiter des données de types spécifiques)
- Apprendre à déboguer et surveiller Logstash en cas de problèmes (par exemple, en utilisant la commande « logstash –config.test_and_exit » pour tester la configuration de Logstash)
- Sécuriser Logstash avec SSL


