IA · GPU · CLOUD · INFRA
Choisir un hébergement GPU IA ne consiste pas à prendre le prix horaire le plus bas. En entreprise, il faut arbitrer entre coût, disponibilité, souveraineté, support, stockage, réseau et capacité à scaler sans transformer l’infrastructure en dette technique.
📋 Au programme
Hébergement GPU IA : quel fournisseur choisir en France, en Europe ou à l’international ?
Le marché du cloud GPU pour l’IA s’est fragmenté. Entre les clouds souverains, les clouds GPU spécialisés, les serveurs dédiés avec RTX, les offres H100/H200/B200 et les marketplaces très agressives, le “meilleur fournisseur” dépend surtout du type de workload et du niveau d’exigence de l’entreprise.
Pour cette V2, l’idée n’est pas de faire une simple liste de providers. Le but est plus utile : identifier les acteurs crédibles, comprendre où se trouve le vrai rapport qualité/prix et éviter l’erreur classique qui consiste à comparer uniquement le prix par GPU-heure sans regarder le reste.
Réponse rapide
En 2026, OVHcloud reste le meilleur compromis global en France, Nebius offre probablement le meilleur rapport qualité/prix visible publiquement en Europe, et Runpod reste le meilleur choix budget/self-serve à l’international. Si le besoin est fortement enterprise ou training à grande échelle, Lambda, Crusoe et CoreWeave montent logiquement dans le classement.
Ce qu’il faut comparer réellement avant de choisir un hébergement GPU IA
Le premier piège consiste à s’arrêter au prix affiché. Un fournisseur peut sembler moins cher à l’heure, puis redevenir plus coûteux dès qu’on ajoute le stockage, le trafic sortant, les snapshots, le support, la réservation ou la difficulté d’exploitation.
Pour une entreprise, il faut comparer au minimum :
✅ Grille de lecture utile
Dit autrement : le bon fournisseur n’est pas forcément le moins cher. C’est celui qui donne le meilleur coût total utile pour le besoin réel de l’équipe.
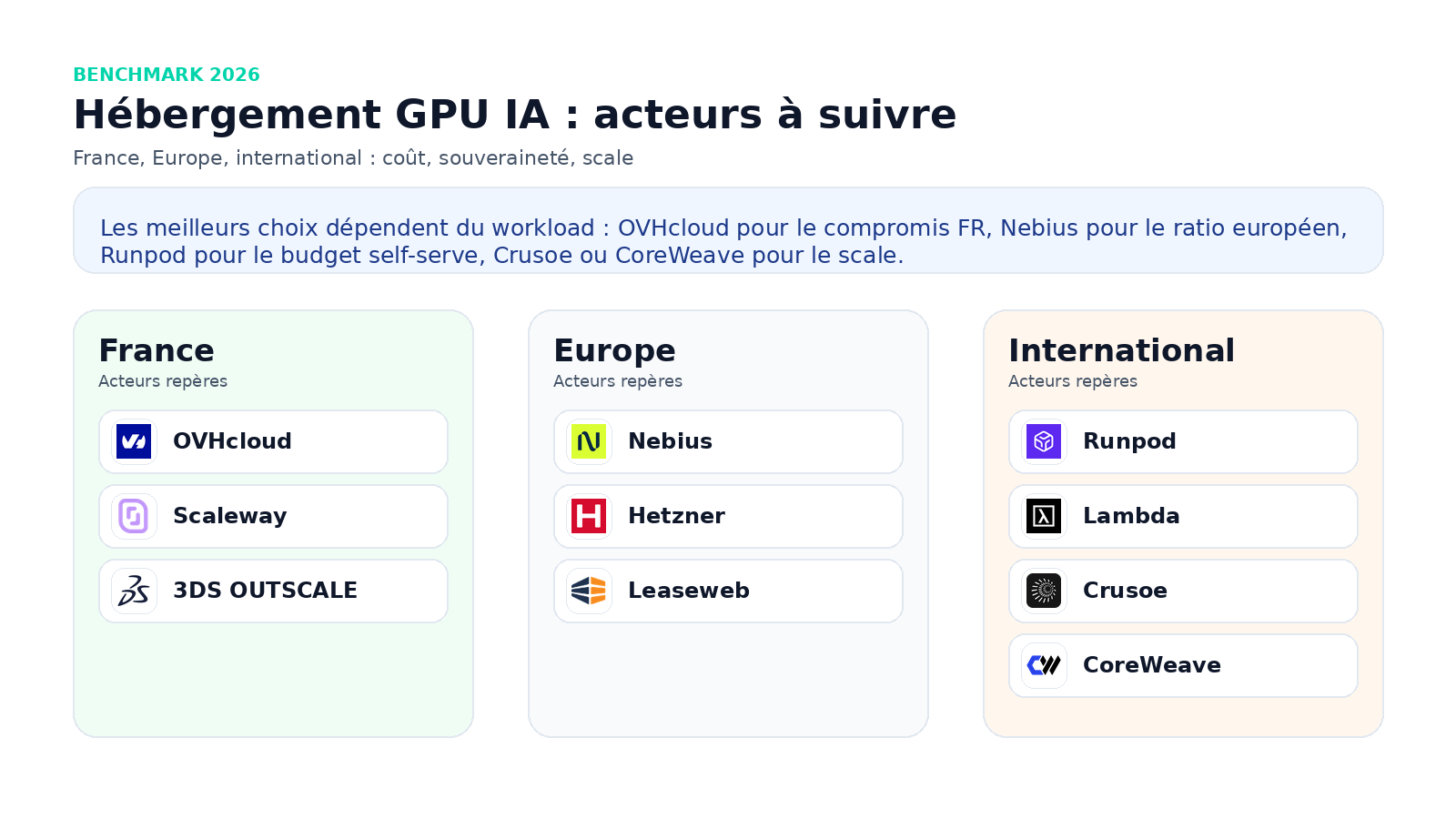
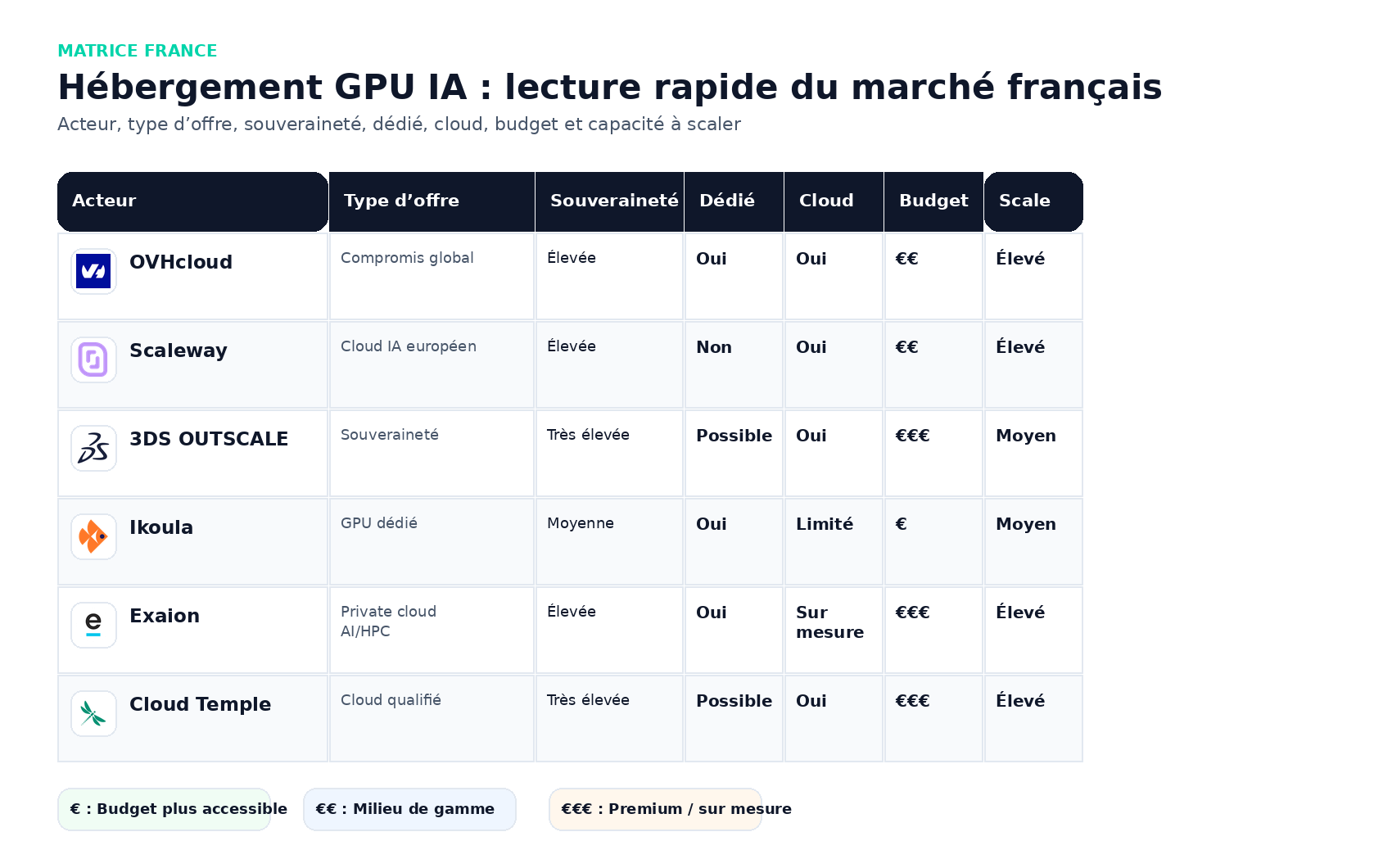
Marché français : les acteurs à suivre

OVHcloud : meilleur compromis global en France
OVHcloud reste l’acteur le plus naturel à recommander à une PME, une ETI ou un éditeur qui veut héberger des workloads IA en Europe avec une image solide côté infrastructure. L’offre GPU couvre H100, A100 et d’autres profils, avec une articulation intéressante entre cloud GPU et bare metal.
Le vrai avantage d’OVHcloud n’est pas d’être systématiquement le moins cher. C’est d’offrir un cadre rassurant : localisation, contrôle des données, offre européenne, crédibilité commerciale et possibilité de construire une architecture plus stable qu’un simple POC GPU improvisé.
À retenir
OVHcloud est souvent le meilleur choix si la décision doit aussi tenir devant un client, une direction ou un RSSI, pas seulement devant un benchmark prix.
Scaleway : cloud IA européen moderne
Scaleway pousse un positionnement très lisible sur les workloads IA européens : L4, L40S, H100 PCIe, H100 SXM et même Blackwell sur certaines gammes. L’offre est cohérente pour des équipes qui veulent un acteur européen plus “cloud-native” et plus produit que certains hébergeurs historiques.
Scaleway me paraît particulièrement bien placé pour :
- inférence privée ou dédiée en Europe ;
- fine-tuning sur des workloads pas encore massifs ;
- SaaS et éditeurs qui veulent éviter une stack trop lourde ;
- entreprises sensibles à la localisation européenne mais pas enfermées dans la seule logique souveraine.
3DS OUTSCALE : souveraineté et conformité d’abord
OUTSCALE joue une autre partition : sécurité, souveraineté, conformité, cloud de confiance. C’est rarement l’acteur le plus agressif en benchmark prix pur, mais il devient pertinent dès que le dossier touche le secteur public, la santé, la défense, l’assurance ou des exigences de conformité fortes.
La bonne façon de le lire n’est pas “est-ce le moins cher ?”, mais plutôt “est-ce le meilleur véhicule pour un besoin GPU dans un cadre fortement contraint ?”. Dans ce cas, la réponse peut devenir oui.
Petits acteurs français à surveiller : là où le benchmark devient plus intéressant
La partie française du marché ne se limite pas aux trois grands noms. En creusant davantage, on trouve aussi plusieurs acteurs plus petits ou plus spécialisés qui méritent d’être cités dès qu’on parle vraiment d’offres GPU en France.
Ikoula : GPU dédiés accessibles et pragmatiques

Ikoula propose une gamme de serveurs dédiés GPU mise en avant sur son site, avec des cartes NVIDIA RTX 4070, 5070 Ti ou RTX Pro 4000 Blackwell. L’angle est moins “AI platform” que chez Scaleway ou Nebius, mais plus direct : des machines GPU dédiées, accessibles, avec un positionnement hébergeur historique.
Concrètement, Ikoula devient intéressant pour des besoins comme :
- hébergement de modèles open source en privé ;
- inférence stable sur GPU dédié ;
- fine-tuning ou expérimentation sur des cartes RTX plus abordables ;
- équipes qui préfèrent garder la main sur l’exploitation plutôt que payer une plateforme IA plus riche.
Le point de vigilance : on est davantage sur une logique serveur GPU que sur un cloud GPU très élastique. Donc excellent pour certains usages maîtrisés, moins pertinent pour des besoins de scale cloud immédiat.
Exaion : private cloud AI / HPC pour environnements sensibles

Exaion se positionne sur le private cloud haute performance pour l’IA et le HPC, avec un discours très clair autour des données sensibles, de l’isolement, de l’open source, du support et des workloads intensifs. Ce n’est pas un acteur “prix catalogue self-serve” : c’est plutôt un fournisseur à regarder quand le sujet devient stratégique ou fortement encadré.
Leur discours met en avant des latest-generation GPUs, du stockage haute performance et des environnements personnalisables. Autrement dit : moins un cloud opportuniste, plus une brique d’infrastructure sur mesure pour entreprises qui veulent du GPU dans un cadre maîtrisé.
Cloud Temple : GPU souverain qualifié, très intéressant pour les contextes réglementés

Cloud Temple va encore plus loin sur la partie confiance : offre GPU dans un cloud souverain, HDS, ISO 27001, SecNumCloud et même C5 selon les pages consultées. Le positionnement est très net : accélérer IA et HPC dans un environnement hautement qualifié.
Ce type d’acteur ne bat pas forcément Runpod ou Nebius sur le coût public brut. En revanche, pour des projets où la conformité, la protection des données, la qualification de l’environnement et la capacité à héberger de l’IA dans une “bulle de confiance” sont structurantes, Cloud Temple mérite clairement sa place dans le benchmark français.
Lecture utile du marché français
OVHcloud, Scaleway et OUTSCALE restent les têtes d’affiche. Mais dès qu’on pousse l’analyse, Ikoula, Exaion et Cloud Temple ajoutent trois angles très différents : GPU dédié accessible, private cloud AI/HPC, et cloud GPU souverain qualifié.
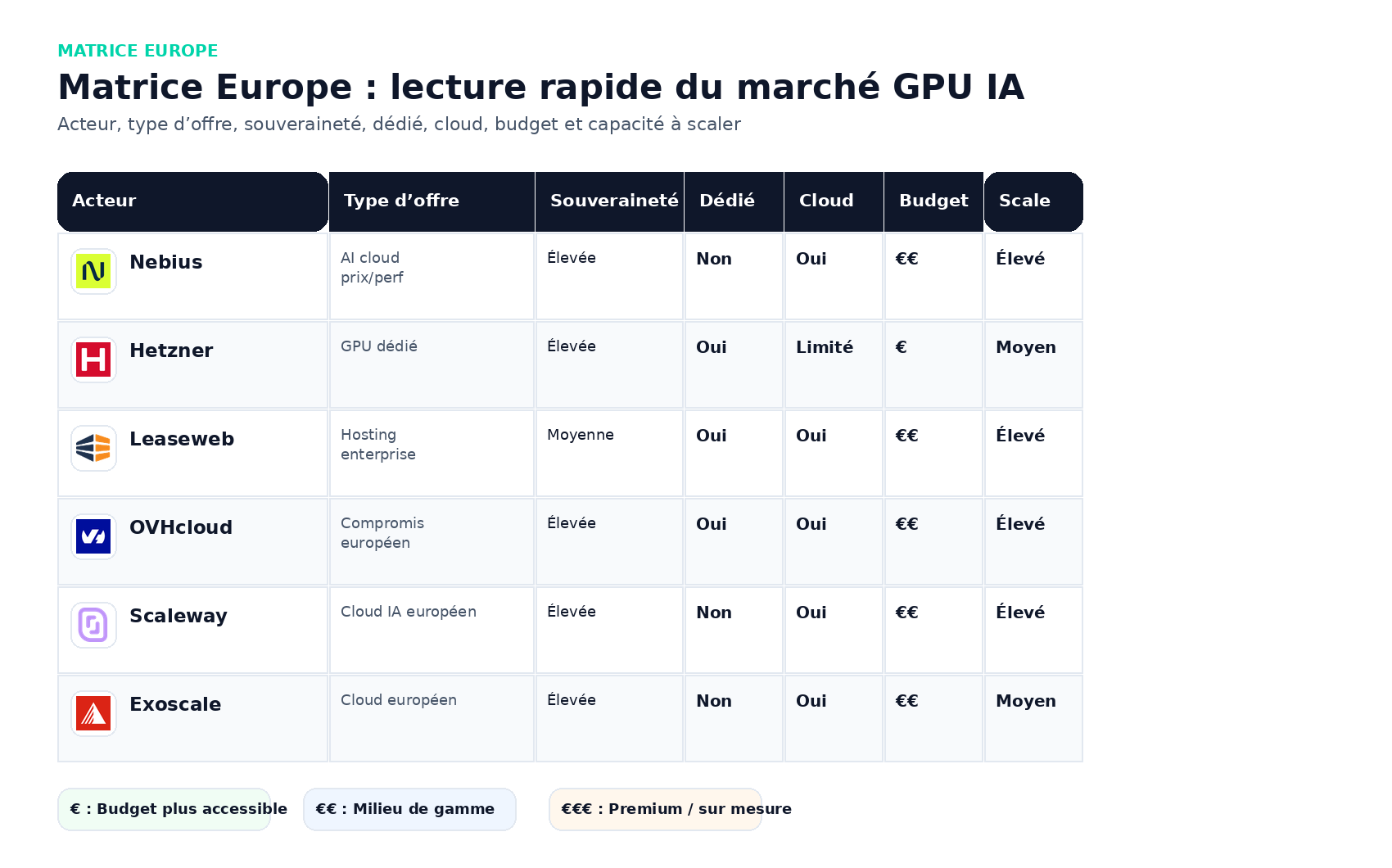
Marché européen : là où le rapport qualité/prix devient intéressant

Nebius : probablement le meilleur rapport qualité/prix public en Europe
Nebius est aujourd’hui l’un des acteurs les plus intéressants à suivre pour les charges IA sérieuses en Europe. L’atout clé : des prix publics lisibles et un portefeuille GPU crédible.
Signaux publics relevés :
- H100 on-demand : $3.85/h
- H100 preemptible : $2.15/h
- H200 : $4.50/h
- RTX PRO 6000 : $1.80/h
- L40S : à partir de $1.55–1.82/h
Ce positionnement est très fort, parce qu’il combine prix compétitifs, ciblage IA explicite, remises d’engagement et une vraie lisibilité pour les workloads inference, fine-tuning et cluster GPU.
Hetzner : excellent coût brut si l’équipe sait opérer
Hetzner joue un rôle différent. On est davantage dans la logique du serveur GPU dédié que dans celle du cloud IA managé premium. C’est très intéressant si l’équipe a de vraies compétences système et veut optimiser le coût total.
Le point fort est simple : on obtient du contrôle, du root, du GPU dédié en Europe, dans un cadre GDPR, souvent avec un rapport prix/performance redoutable sur des cartes RTX ou Ada. En revanche, l’expérience sera moins confortable si l’objectif est d’avoir une plateforme MLOps riche ou du multi-node prêt à l’emploi.
Leaseweb : crédible en enterprise, moins lisible en self-serve
Leaseweb reste un nom crédible dans l’hébergement enterprise multi-pays. En revanche, du point de vue d’un benchmark public rapide, l’offre GPU est moins transparente que celle de Nebius, Runpod ou Lambda. C’est davantage un candidat à regarder pour des besoins négociés, sur mesure, ou des architectures dédiées à forte composante réseau/hébergement.
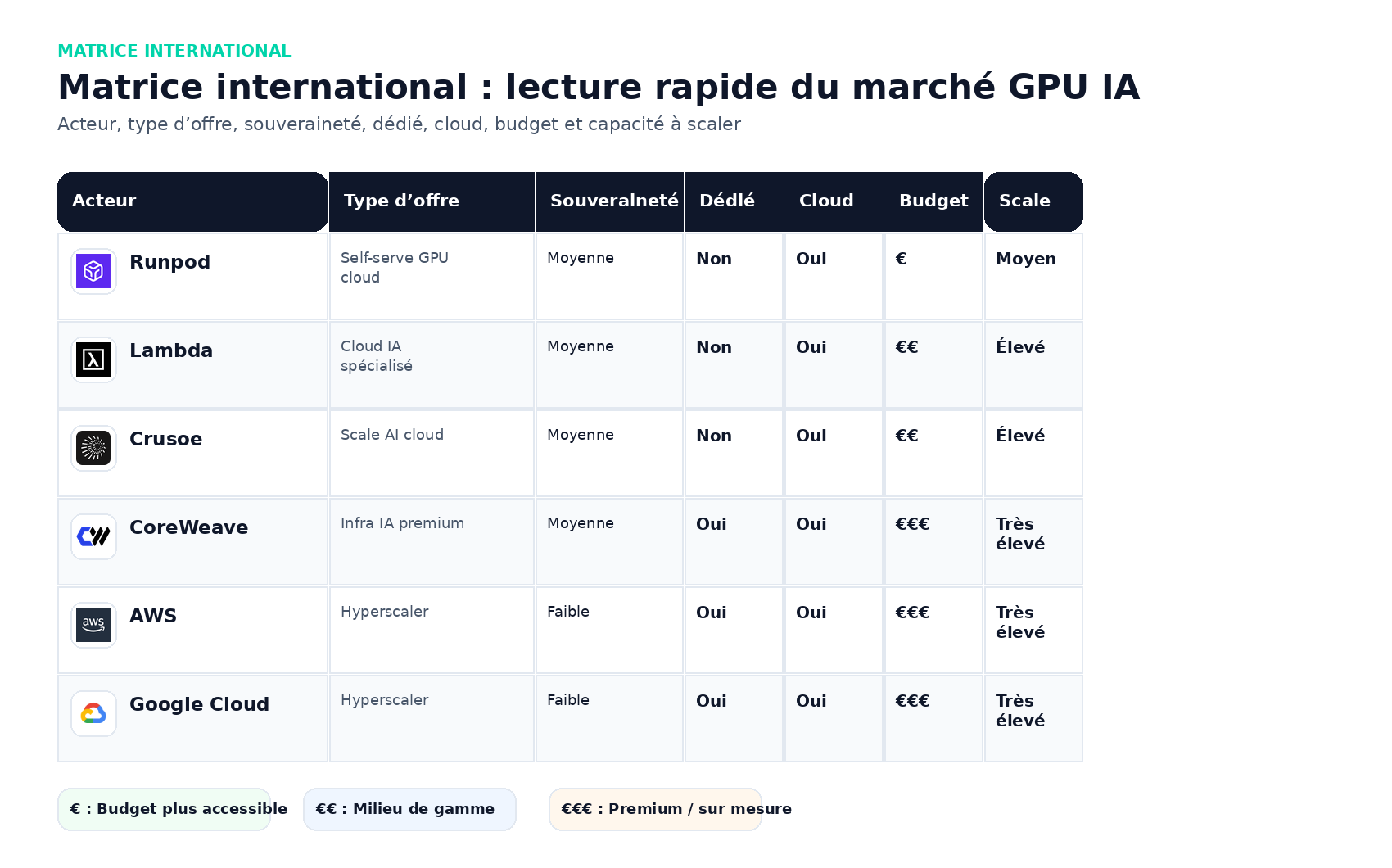
Marché international : le match prix, simplicité et scale

Runpod : meilleur choix budget/self-serve
Runpod reste l’un des acteurs les plus agressifs pour lancer rapidement des workloads IA sans basculer sur un hyperscaler coûteux. Les prix publics relevés sont très compétitifs :
- H100 PCIe : $2.89/h
- H100 SXM : $3.29/h
- A100 PCIe 80 GB : $1.39/h
- A100 SXM 80 GB : $1.49/h
- L40S : $0.99/h
- L4 : $0.39/h
Pour un POC, une startup IA, de l’inférence ou du fine-tuning opportuniste, c’est difficile à ignorer. En revanche, pour des comptes sensibles, il faut aussi regarder la perception enterprise, le support et le niveau d’encadrement attendu.
Lambda : très bon compromis entre spécialisation IA et lisibilité
Lambda est souvent plus simple à recommander qu’un acteur très low-cost, car la marque est clairement positionnée IA et l’offre est lisible. Les prix publics relevés sont moins agressifs que Runpod sur certains profils, mais restent compétitifs :
- H100 SXM : $3.99/h
- A100 80 GB : $2.79/h
- A100 40 GB : $1.99/h
- B200 : $6.69/h
Lambda devient très pertinent si l’entreprise veut un spécialiste IA crédible, simple à comprendre, sans devoir passer par une marketplace opportuniste ou un hyperscaler plus complexe.
Crusoe : très bon angle scale et valeur globale
Crusoe monte bien dans les classements dès que le besoin dépasse le simple “je veux le moins cher possible”. Les prix publics relevés restent solides :
- H100 HGX : $3.90/h
- H200 : $4.29/h
- A100 80 GB SXM : $2.30/h
- A100 80 GB PCIe : $2.00/h
- L40S : $1.50/h
- MI300X : $3.45/h
Le vrai intérêt de Crusoe est sa capacité à devenir un bon choix quand il faut scaler proprement, réserver, industrialiser et sortir d’un mode purement opportuniste.
CoreWeave : très fort techniquement, plus premium
CoreWeave reste l’un des acteurs les plus crédibles sur l’infrastructure IA lourde. La plateforme est clairement orientée training, scale, orchestration et workloads complexes. En revanche, la lecture prix est moins “petit budget” et davantage enterprise. Pour une PME ou une ETI sans besoin de cluster conséquent, ce n’est pas forcément le meilleur rapport qualité/prix. Pour un gros besoin training, c’est une autre histoire.
AWS, GCP, Azure : rarement les moins chers, souvent les plus complets
Les hyperscalers gardent un avantage évident dès que le sujet dépasse le simple GPU : IAM, réseau, sécurité, observabilité, interconnexion, services managés, conformité, gouvernance et intégration au SI. En revanche, sur du coût GPU brut, ils sont rarement les champions. C’est souvent le bon choix si l’entreprise a déjà standardisé une partie de son infrastructure dessus.
Tableau comparatif qualité/prix
| Acteur | Marché | Point fort | Lecture prix/perf | Meilleur usage |
|---|---|---|---|---|
| OVHcloud | France / Europe | Compromis global, crédibilité, localisation | Pas toujours le moins cher, souvent le plus vendable | PME, ETI, workloads IA hébergés en Europe |
| Scaleway | France / Europe | Cloud IA moderne, offre GPU cohérente | Très bon, surtout pour un usage product/cloud-native | Inference, fine-tuning, SaaS européens |
| 3DS OUTSCALE | France | Souveraineté, conformité, sécurité | Faible en benchmark prix brut, fort en cadre réglementaire | Public, santé, assurance, dossiers sensibles |
| Nebius | Europe | Prix publics agressifs + vraie spécialisation IA | Excellent | Inference, fine-tuning, clusters GPU sérieux |
| Hetzner | Europe | Serveur GPU dédié à très bon coût | Excellent si l’équipe sait opérer seule | Inference privée, lab GPU, workloads dédiés |
| Runpod | International | Prix, rapidité, self-serve | Excellent en budget | POC, startup IA, fine-tuning, inference |
| Lambda | International | Spécialiste IA lisible et rassurant | Très bon compromis | Équipes IA voulant simplicité et crédibilité |
| Crusoe | International | Montée en charge propre, GPU modernes | Très bon pour scale et valeur globale | Training, fine-tuning, clusters sérieux |
| CoreWeave | International | Infra IA premium et très forte techniquement | Fort en qualité, moins fort en petit budget | Training lourd, scale enterprise |
Quel fournisseur choisir selon le profil de l’entreprise ?
Voici une lecture plus directe, orientée décision :
🇫🇷
PME / ETI française
OVHcloud en premier, Scaleway en alternative si l’approche cloud IA native est prioritaire.
🌍
Scale-up ou éditeur européen
Nebius si l’objectif principal est le rapport qualité/prix, Scaleway si l’on veut un acteur européen plus immédiatement “produit”.
⚖️
Secteur régulé
OUTSCALE en tête si la souveraineté est non négociable ; OVHcloud si l’exigence est forte mais pas au niveau du dossier souverain le plus contraint.
🚀
Startup IA / POC rapide
Runpod pour le budget et la vitesse, Lambda si l’on veut un acteur plus lisible côté image et gouvernance.
Enfin, si le besoin est un training lourd multi-node, il faut sortir de la logique “prix public le plus bas” et regarder sérieusement Crusoe, CoreWeave et, selon le contexte européen, Nebius.
Dans le cas français, il faut aussi distinguer les besoins : Ikoula pour du GPU dédié plus direct et plus simple à louer, Exaion pour un private cloud AI/HPC plus structuré, et Cloud Temple pour les projets où la qualification de l’environnement compte presque autant que la puissance GPU elle-même.
Erreurs courantes dans le choix d’un cloud GPU
💸 Comparer seulement le prix GPU horaire
C’est l’erreur la plus fréquente. Le stockage, l’egress, les snapshots, la dispo réelle et le temps humain d’exploitation changent complètement le coût réel.
🔐 Oublier la souveraineté trop tôt
Un projet IA B2B peut très bien avancer avec un fournisseur international… jusqu’au moment où un client demande où tournent les modèles et où sont stockées les données.
🧱 Prendre un cloud GPU “plateforme” pour un besoin qui relève d’un serveur dédié
Pour certains cas d’inférence privée ou d’hébergement de modèles open-source, un bon serveur GPU dédié peut battre un cloud IA premium sur le coût total.
📈 Sous-estimer la phase de scale
Un fournisseur parfait pour un POC ne sera pas forcément le bon pour industrialiser, réserver des capacités ou faire tourner un cluster d’entraînement en production.
Conclusion : le bon fournisseur GPU n’est pas le même selon le niveau d’exigence
Pour une entreprise française, le meilleur choix n’est pas universel. Si l’on veut un compromis rassurant, OVHcloud tient bien la route. Si l’on cherche une offre GPU européenne moderne, Scaleway est très crédible. Si l’on vise le meilleur rapport qualité/prix visible publiquement en Europe, Nebius est probablement le plus agressif. Si l’on veut itérer vite à bas coût, Runpod garde une longueur d’avance. Et dès qu’il faut scaler proprement, Lambda, Crusoe et CoreWeave reprennent du poids.
Le bon angle de décision reste simple : workload, souveraineté, support, coût total. C’est ce qu’il faut cadrer avant de signer ou de déployer.
FAQ hébergement GPU IA
Besoin d’arbitrer entre cloud GPU, serveur dédié et hébergement souverain ?
Linux-Man peut t’aider à cadrer le bon fournisseur, le bon niveau de souveraineté et le vrai coût d’exploitation avant déploiement.

