DNS · PRODUCTION · SÉCURITÉ
Une simple zone mal relue peut couper les emails, invalider un certificat ou rendre une application invisible. Ce guide aide à identifier les erreurs DNS production avant qu’elles ne deviennent un incident client.
📋 Au programme
Réponse rapide
Pour éviter les erreurs DNS en production, validez toujours les enregistrements critiques avant changement, réduisez le TTL avant migration, testez les résolutions depuis plusieurs réseaux, surveillez MX/SPF/DKIM/DMARC et documentez chaque dépendance applicative. Le DNS doit être traité comme un composant de production, pas comme un simple formulaire chez le registrar.

Le bon réflexe
Avant un changement, capturez l’état actuel avec dig et gardez un plan de retour arrière.
Pourquoi le DNS casse autant de services
En PME comme dans une équipe produit, le DNS est souvent partagé entre le registrar, l’hébergeur, un prestataire email, un CDN, un reverse proxy et parfois un fournisseur cloud. Cette fragmentation crée un risque : chacun voit une petite partie de la chaîne, mais personne ne possède vraiment la cohérence globale. Quand un changement est fait dans l’urgence, il peut casser un service sans générer d’erreur évidente dans les logs applicatifs.
Les impacts les plus visibles concernent les emails, les certificats TLS/SSL et la disponibilité web. Un mauvais MX ralentit ou bloque la réception. Un SPF trop large ou mal formé dégrade la délivrabilité. Un CNAME supprimé empêche le renouvellement automatique d’un certificat. Un TTL trop élevé allonge un incident pourtant corrigé côté configuration. Ces problèmes semblent différents, mais ils ont la même racine : une gouvernance DNS insuffisante.
✉️
Emails
MX, SPF, DKIM et DMARC conditionnent réception et réputation.
🔐
TLS/SSL
ACME et challenges DNS dépendent de noms cohérents.
🌍
Disponibilité
Une erreur A/AAAA/CNAME rend le service inaccessible.
Diagnostic DNS en production
Le diagnostic commence par une comparaison entre l’intention et la réalité. Listez les services exposés, les noms attendus, les fournisseurs concernés et les enregistrements indispensables. Ensuite, vérifiez la résolution depuis plusieurs points : votre réseau, un résolveur public, et si possible un serveur externe. Une anomalie visible sur un seul résolveur peut être liée au cache ; une anomalie visible partout indique plutôt une erreur de zone.
dig +short MX exemple.fr
dig +short TXT exemple.fr
dig +trace app.exemple.fr
openssl s_client -connect app.exemple.fr:443 -servername app.exemple.frPour les emails, contrôlez la priorité des MX, la présence d’un seul SPF valide, la signature DKIM active côté fournisseur et une politique DMARC progressive. Pour le web, vérifiez que le nom public pointe vers la bonne cible, que les AAAA ne renvoient pas vers une IPv6 non servie, et que le certificat présenté correspond bien au Server Name Indication attendu.
Causes fréquentes
La première cause est le copier-coller partiel. On migre un site, mais on oublie un sous-domaine d’API, un CNAME de validation ou un TXT utilisé par un fournisseur. La deuxième est la confusion entre zone autoritaire et interface DNS secondaire : modifier le mauvais panneau ne change rien en production. La troisième est le TTL mal anticipé. Si le TTL reste à plusieurs heures, une correction peut mettre longtemps à se propager côté caches récursifs.
Attention aux SPF multiples
Un domaine ne doit pas publier plusieurs enregistrements SPF. Fusionnez les sources dans un seul TXT commençant par v=spf1.
Les erreurs IPv6 sont également fréquentes. Un enregistrement AAAA ajouté automatiquement peut envoyer une partie du trafic vers une adresse non routée ou un service non configuré. Enfin, les délégations NS oubliées provoquent des situations trompeuses : l’interface affiche la bonne valeur, mais les serveurs autoritaires consultés par Internet répondent autre chose.
Solutions concrètes
La solution n’est pas seulement technique : elle est organisationnelle. Centralisez l’inventaire DNS, associez chaque enregistrement à un service et à un responsable, puis imposez une procédure de changement. Avant une migration, baissez le TTL 24 à 48 heures avant si possible. Après modification, vérifiez les réponses autoritaires et récursives. Pour les emails, validez SPF, DKIM et DMARC avec les outils du fournisseur mais aussi avec des requêtes DNS brutes.
# Identifier les serveurs autoritaires
dig NS exemple.fr +short
# Interroger directement un serveur autoritaire
dig @ns1.exemple.fr app.exemple.fr A
# Vérifier les TXT utiles aux emails
dig exemple.fr TXT +short
dig selector._domainkey.exemple.fr TXT +short
dig _dmarc.exemple.fr TXT +shortQuand la disponibilité est critique, ajoutez une supervision DNS indépendante. Surveiller uniquement le serveur web ne suffit pas : si le DNS est cassé, votre monitoring interne peut continuer à voir le service tandis que les utilisateurs ne le résolvent plus. Une sonde externe doit tester le nom public, la réponse attendue, le certificat et le temps de résolution.
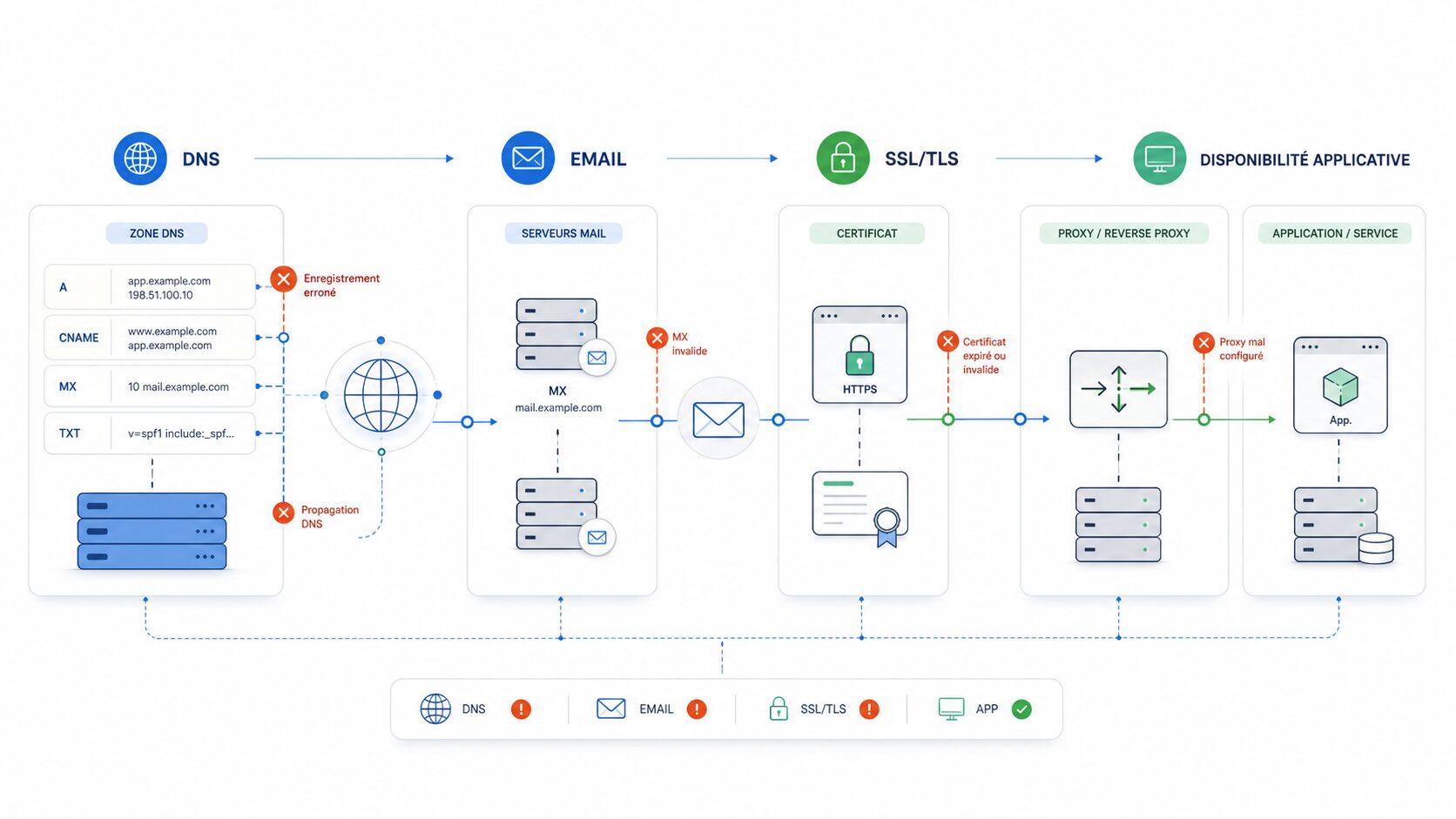
Prévention et monitoring
La prévention repose sur trois pratiques : versionner, relire, surveiller. Versionner ne veut pas forcément dire déployer toute la zone avec Infrastructure as Code dès le premier jour. Un export régulier, un journal de changement et une convention de nommage apportent déjà beaucoup. La relecture doit inclure les dépendances métier : qui utilise ce sous-domaine, quel fournisseur le valide, quel risque si l’entrée disparaît ?
Bonne pratique
Créez une alerte si un enregistrement critique change ou disparaît, notamment MX, TXT SPF/DMARC et les CNAME de validation.
Pour aller plus loin, vous pouvez coupler supervision DNS, supervision certificat et tests applicatifs. Le DNS répond ? Le certificat est valide ? L’application retourne-t-elle le bon code HTTP ? C’est cette chaîne complète qui reflète l’expérience utilisateur.
Checklist de mise en production
✅ Checklist DNS avant changement
dig NSCette checklist doit être utilisée avant chaque changement de zone, même lorsqu’il semble mineur. En DNS, un caractère oublié suffit à transformer une maintenance de cinq minutes en incident de plusieurs heures.
Erreurs courantes
⏱ TTL oublié
Le TTL reste trop haut avant migration. Réduisez-le en amont, puis remontez-le après stabilisation.
📮 SPF cassé
Plusieurs SPF ou trop d’includes entraînent des échecs. Nettoyez et testez après chaque ajout de fournisseur email.
🌐 AAAA non maîtrisé
Une IPv6 publiée sans service prêt crée des erreurs intermittentes pour certains utilisateurs.
FAQ
Aller plus loin après le diagnostic DNS
La page déploiements et automatisation serveurs aide à cadrer l’industrialisation. La page maintenance serveurs Linux PME couvre le suivi opérationnel. Et pour le pilotage global de l’exploitation Linux, l’infogérance Linux pour PME complète la démarche.
Conclusion
Les erreurs DNS en production ne sont pas spectaculaires au moment où elles sont commises, mais elles deviennent vite coûteuses : emails non reçus, certificats impossibles à renouveler, application inaccessible ou migration qui semble aléatoire. En traitant le DNS comme un composant de production, avec inventaire, relecture, tests et supervision, vous réduisez fortement ce risque.
Si votre zone DNS a grandi au fil des prestataires et des urgences, un audit court permet souvent de repérer les entrées orphelines, les dépendances critiques et les points faibles avant incident. C’est un chantier simple, très rentable, et souvent oublié jusqu’au jour où il bloque toute l’activité.
À lire aussi : maintenance serveur Linux et supervision serveur Linux.
Besoin de fiabiliser votre DNS de production ?
Linux-Man peut auditer vos zones, sécuriser vos changements et mettre en place une supervision DNS, email et TLS.