SUPERVISION LINUX · OPS · PME
Une supervision serveur Linux utile ne se juge pas au nombre de métriques collectées. Elle doit surtout prévenir la bonne personne, au bon moment, avec assez de contexte pour décider vite.

Pour réduire le bruit des alertes, commencez par classer les services critiques, définir des seuils orientés impact utilisateur, supprimer les alertes sans action possible, puis relier chaque notification à une procédure. Une bonne supervision serveur Linux surveille les bons signaux et déclenche au bon moment.
🔕
Moins d’alertes
Une alerte inutile finit par être ignorée, même lorsqu’elle annonce ensuite une vraie panne.
🎯
Impact métier
Les seuils doivent traduire un impact concret : disponibilité, lenteur, sauvegarde ou capacité.
📘
Procédure obligatoire
Si personne ne sait quoi faire après notification, l’alerte doit être enrichie, déclassée ou supprimée.
📋 Au programme
Pourquoi la supervision serveur Linux devient bruyante
Dans beaucoup de PME, la supervision commence sainement. On installe un agent, on collecte CPU, RAM, disque, réseau, services, certificats et sauvegardes. Puis chaque nouvel incident ajoute une règle.
Six mois plus tard, l’équipe reçoit des notifications de nuit pour un pic CPU sans impact, un disque presque plein sur une VM de test ou un service qui redémarre automatiquement.
Le bruit détruit la confiance
Quand une alerte sonne souvent pour rien, l’équipe apprend à l’ignorer. Le risque n’est pas technique, il est opérationnel.
Le vrai problème n’est donc pas l’outil. Zabbix, Prometheus, Grafana, Centreon ou une solution SaaS peuvent tous produire un excellent résultat.
Le problème vient surtout d’un manque de cadrage : pas de criticité, pas de propriétaire, pas de silence pendant maintenance, pas de procédure et pas de revue régulière.
Le modèle d’alerte utile : impact, action, propriétaire
Une alerte utile respecte trois critères. Elle décrit un impact probable, propose une action claire et cible un propriétaire capable de décider.
Si l’un de ces critères manque, le signal doit rester visible dans un dashboard, un rapport quotidien ou une tâche de maintenance. Il ne doit pas réveiller l’astreinte.
Flux à garder en tête
Le point de contrôle n’est pas la métrique brute. C’est la décision possible après réception de l’alerte.
Pour un serveur web, un CPU à 92 % pendant deux minutes n’est pas forcément critique. Une hausse simultanée du temps de réponse, des erreurs 5xx et de la saturation PHP-FPM l’est beaucoup plus.
Cette logique réduit les faux positifs. Elle permet aussi d’expliquer les alertes à une direction non technique, car le langage devient celui du service rendu.
Architecture simple pour une petite équipe d’exploitation
Une architecture efficace peut rester sobre : collecte locale, stockage métriques, moteur d’alertes, canal de notification et documentation opérationnelle.
Le plus important est d’éviter la confusion entre observation et interruption. Toutes les métriques ne méritent pas une notification immédiate.
🖥️
Serveurs critiques
ERP, site web, bastion, DNS interne, sauvegarde et hyperviseurs.
📊
Dashboards
Vue disponibilité, capacité disque, sauvegardes, certificats et latence.
📣
Alertes
Seulement les signaux qui demandent une action rapide et connue.
📚
Procédures
Chaque alerte renvoie vers une procédure courte, testée et maintenue.
Pour approfondir la stack technique, l’article sur Grafana, Prometheus et le monitoring assisté par IA complète cette approche.
Si votre parc Linux manque d’inventaire fiable, commencez aussi par automatiser la collecte avec Ansible gather_facts.
Prioriser les alertes : criticité, SLA et fenêtres de maintenance
La priorisation évite de traiter tous les serveurs avec le même niveau d’urgence. Un serveur de test, un reverse proxy public et une base de données métier ne doivent pas partager les mêmes règles.
Commencez par une matrice simple. Classez chaque service en critique, important ou non prioritaire. Associez ensuite une plage de notification, un délai acceptable et un canal adapté.
Exemple simple
Une sauvegarde échouée peut être critique au début de la journée, mais inutile à notifier trois fois dans la nuit si personne ne peut agir avant 8 h.
Les fenêtres de maintenance sont tout aussi importantes. Sans silence planifié, chaque redémarrage volontaire devient un faux incident et abîme la confiance dans l’outil.
Documentez aussi les dépendances. Une panne DNS interne peut créer dix alertes applicatives. L’alerte source doit être visible, les alertes secondaires doivent être regroupées.
Cette logique rapproche le monitoring du service réel. Elle aide une direction à comprendre pourquoi certaines alertes sont immédiates et pourquoi d’autres restent dans un rapport.
Mini-lab : tester une alerte utile avec Prometheus et Alertmanager
Ce mini-lab reste volontairement local. Il sert à valider la logique d’alerte, pas à remplacer une architecture de production.
Périmètre sûr
Lancez ce test sur une VM, un poste local ou un environnement de sandbox. Ne branchez pas encore le canal d’astreinte réel.
Pré-requis : Docker, un répertoire de test et les ports 9090 et 9093 libres. L’objectif est de déclencher une alerte contrôlée.
mkdir -p monitoring-lab
cd monitoring-lab
cat > prometheus.yml <<'EOF'
global:
scrape_interval: 15s
rule_files:
- rules.yml
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['prometheus:9090']
EOF
cat > rules.yml <<'EOF'
groups:
- name: linuxman-demo
rules:
- alert: PrometheusTargetDown
expr: up{job="prometheus"} == 0
for: 1m
labels:
severity: warning
service: monitoring-lab
annotations:
summary: "Prometheus ne parvient plus à se superviser lui-même"
procédure: "Vérifier conteneur, réseau Docker et configuration scrape"
EOFAjoutez ensuite Alertmanager et Prometheus dans un fichier Compose minimal.
cat > docker-compose.yml <<'EOF'
services:
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml:ro
- ./rules.yml:/etc/prometheus/rules.yml:ro
ports:
- "9090:9090"
command:
- "--config.file=/etc/prometheus/prometheus.yml"
alertmanager:
image: prom/alertmanager:latest
ports:
- "9093:9093"
EOF
docker compose up -dRésultat attendu : Prometheus répond sur le port 9090 et Alertmanager sur le port 9093. L’alerte ne doit pas être active tant que la cible est saine.
curl -s http://localhost:9090/-/healthy
curl -s http://localhost:9093/-/healthyPour vérifier le déclenchement, arrêtez Prometheus après avoir observé l’état initial. Dans un vrai environnement, simulez plutôt une cible applicative dédiée.
docker compose stop prometheus
# Attendre au moins une minute, puis consulter Alertmanager.
# Rollback / nettoyage :
docker compose up -d prometheus
docker compose downCe test montre l’essentiel : l’alerte contient une sévérité, un service, un résumé et une piste de procédure. C’est ce format qui rend l’alerte actionnable.
KPI et revue mensuelle : là où la supervision devient pilotable
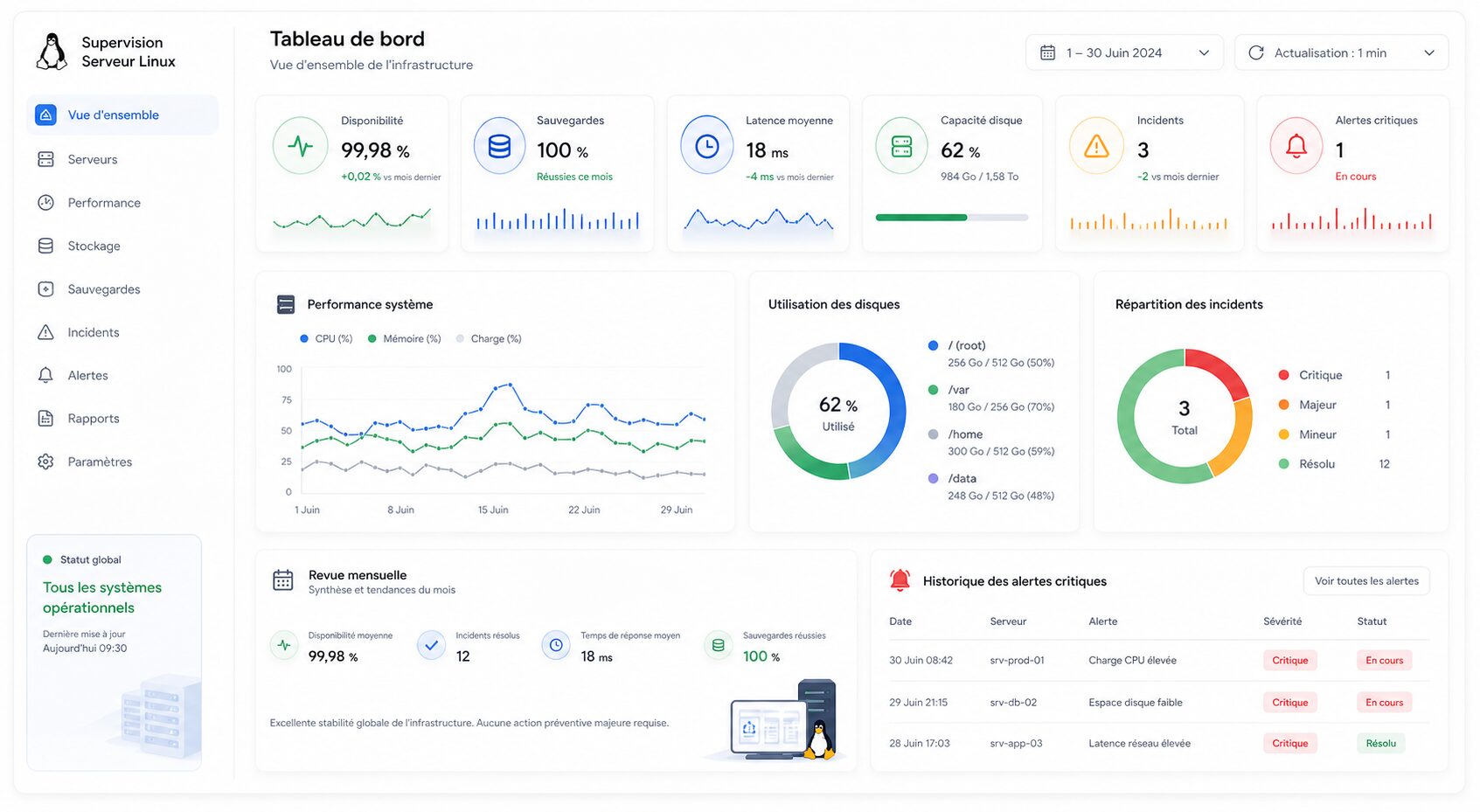
Une supervision n’est vraiment utile que si elle nourrit une revue d’exploitation simple et régulière. Sans cela, les alertes s’accumulent, mais les causes récurrentes restent en place.
Disponibilité
Quels services critiques ont réellement été indisponibles, combien de temps et avec quel impact ?
Sauvegardes
Les jobs réussissent-ils, et surtout les restaurations ont-elles été vérifiées ?
Capacité
Disque, mémoire, latence et saturation montent-ils sur des services précis ?
Incidents récurrents
Quelles alertes reviennent encore et méritent une action de fond plutôt qu’un simple acquittement ?
Rythme recommandé
Une revue hebdomadaire suffit souvent pour les alertes actives. Une revue mensuelle plus structurée permet ensuite de suivre les tendances, le bruit résiduel, les incidents critiques et les actions de maintenance à lancer.
Checklist avant mise en production
✅ Contrôles indispensables
Revue mensuelle
Gardez un rituel simple : top alertes bruyantes, incidents manqués, seuils à ajuster et procédures à corriger.
Enfin, mesurez le volume d’alertes réellement reçues. Si une équipe reçoit vingt notifications par jour sans incident majeur, la configuration mérite une revue. Le bon indicateur n’est pas seulement le temps de résolution : c’est aussi le ratio entre alertes déclenchées, alertes utiles et incidents réellement évités.
Erreurs courantes dans le monitoring serveur entreprise
⏱ Alerter trop tôt
Un seuil instantané peut déclencher sur des pics normaux. Ajoutez une durée minimale, une moyenne ou une corrélation.
📦 Surveiller les mauvais volumes
Un disque système et un volume temporaire ne méritent pas la même urgence.
🧭 Oublier le procédure
Une alerte sans procédure transfère le stress au technicien, sans accélérer la résolution.
FAQ
Conclusion : une supervision serveur Linux qui aide vraiment l’équipe
Une supervision serveur Linux réussie ne cherche pas à tout notifier. Elle distingue ce qui mérite une interruption immédiate, ce qui demande une analyse et ce qui doit simplement rester visible.
Pour une petite équipe d’exploitation, cette discipline change tout. Moins de bruit, plus de contexte et des procédures claires rendent les incidents plus courts et moins stressants.
Aller plus loin côté run
Si tu veux transformer un monitoring bruyant en exploitation cadrée, regarde aussi la page maintenance serveurs Linux PME. Et si le sujet dépasse l’outillage pour aller vers le pilotage global, l’infogérance Linux pour PME donne le cadre d’accompagnement continu. Pour standardiser la chaîne de déploiement qui alimente ensuite la supervision, la page déploiements et automatisation serveurs complète le dispositif.
Besoin d’un monitoring plus calme et plus fiable ?
Linux-Man peut auditer vos alertes, structurer vos dashboards et remettre vos procédures au centre de l’exploitation.


